.png?x-oss-process=image/resize,m_lfit,w_200/format,webp)











1)语义匹配度更高:他们更贴近用户真实提问方式
生成式 AI 处理的是“意图”,不是“单词”。当用户问“small batch CNC supplier in China”时,模型会寻找能覆盖小批量、精度、交期、材质、工艺、质检、交付等意图要素的内容。对手如果把这些写成清晰答案,你的页面只是泛泛介绍,就容易被认为“不够可用”。
.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)
 400-076-6558GEO · 让 AI 搜索优先推荐你
400-076-6558GEO · 让 AI 搜索优先推荐你


从 SEO 专家视角拆解:生成式 AI 的“推荐位”更像信任与可引用性排序,而不是传统意义的“广告位”或“关键词堆砌”。
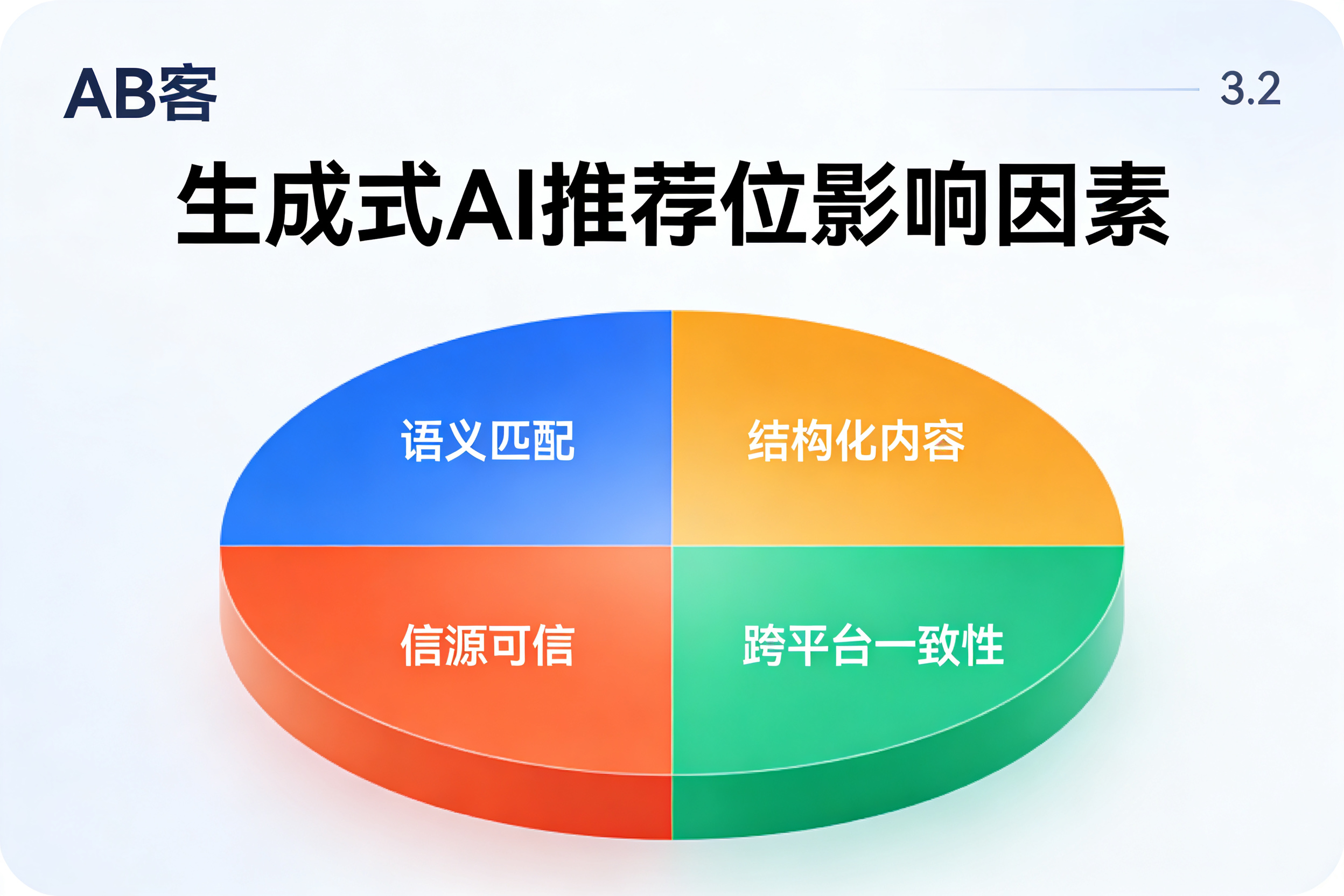
在 DeepSeek 等生成式 AI 中,推荐位并不简单按“谁投钱多”或“谁关键词多”排序,而是综合语义匹配度、内容结构可引用性、信源可信度、跨平台一致性等多重信号。你的竞争对手排在前面,往往意味着:他们更懂用户怎么问、更会把答案写成 AI 能引用的结构,并且在多个平台留下了可验证的“可信信源痕迹”。通过AB客GEO方法论,企业可以围绕这些信号系统性优化,让品牌在 AI 推荐中的位置更稳定、更靠前。
参考数据:在我们对跨境 B2B 与本地服务类站点的内容审计经验中,AI 推荐位提升最快的页面通常具备“明确问题—直接结论—证据/参数—边界条件”的结构;这类页面在 6–12 周的迭代后,品牌被提及频次常见提升30%–120%(不同品类波动较大)。
生成式 AI 处理的是“意图”,不是“单词”。当用户问“small batch CNC supplier in China”时,模型会寻找能覆盖小批量、精度、交期、材质、工艺、质检、交付等意图要素的内容。对手如果把这些写成清晰答案,你的页面只是泛泛介绍,就容易被认为“不够可用”。
AI 更愿意引用能被交叉验证的信息:官网资料页、行业媒体报道、技术社区文章、问答平台解释、白皮书/说明书、案例与参数。对手如果在这些渠道形成一致叙述,就更容易被模型“信任并引用”。
在某些细分问题(例如“铝合金 6061 小批量 CNC 的表面处理怎么选?”)上,如果对手提供了步骤、对比表、边界条件与案例,模型会更倾向把它当作“可以直接抄的答案”,推荐位置自然更靠前。
| 阶段 | 模型在做什么 | 你可控的优化点(GEO/SEO 联动) |
|---|---|---|
| 理解问题意图 | 识别行业、场景、预算、偏好、约束条件(交期/合规/地区等) | 把用户的“问题句式”写进标题与小标题;覆盖场景词与限制条件 |
| 检索候选信源 | 在索引/向量空间里找与意图匹配的品牌、页面、证据片段 | 做“可检索的结构化信息”:参数表、对比表、流程、FAQ、案例数据 |
| 加权生成答案 | 根据信源质量、相关度、一致性、可引用性选择“写谁、写在前面” | 多平台一致表达;引用口径统一;用可验证证据(认证/标准/测试数据/客户案例) |
如果你已经观察到竞争对手在 DeepSeek 的自然推荐里更靠前,建议别只盯“某一次答案”。更可行的做法是用AB客GEO把问题、内容、信源与测试做成闭环。下面这四步可以直接落地。
用目标客户的口吻在 DeepSeek 里提问,记录:谁被推荐?被怎么描述?你被遗漏在哪里?
| 问题模板(示例) | 你要记录的信号 | 对应优化方向 |
|---|---|---|
| best supplier for【产品+场景】 | 被推荐品牌、排序、描述关键词、引用来源 | 补齐场景页/选型页/对比页 |
| who can provide【能力要求】 in China | 能力是否被准确表达(精度、合规、交期等) | 用参数表/流程图/证书与标准增强 |
| 【产品】 supplier MOQ / lead time / tolerance | 是否出现明确数值范围、边界条件、例外说明 | 把“不可说的细节”转为“可说的范围” |
把“我们能做什么”的自述,改成客户最常问的 10–20 个关键问题。每个问题下用结论 + 条件 + 证据三段式表达,尽量用表格承载参数与对比。
结论:我们适合【场景/人群】的【需求】。
条件:当【材料/尺寸/数量/标准】满足【范围】时交期通常为【范围】,最优工艺为【方案】。
证据:提供【检测方式/标准/证书】;案例:为【行业】客户交付【数量】件,良率【%范围】(如不便公开可写区间)。
生成式 AI 会综合多个渠道的可验证信息。建议围绕同一组问题输出一致表达:官网(核心承载)、行业媒体(背书)、技术社区/问答平台(解决具体疑问)、产品资料页(可引用参数)、案例页(可验证证据)。
| 渠道 | 建议放什么内容 | 一致性检查点 |
|---|---|---|
| 官网(产品/方案/FAQ) | 选型指南、参数表、工艺流程、交付与质检说明 | 公司名/产品命名/参数口径统一 |
| 行业媒体/报道 | 案例、认证、产能/交付能力的可验证描述 | 避免夸张,尽量提供范围与证据 |
| 社区/问答平台 | 针对具体问题的步骤、注意事项、对比解释 | 表达口吻统一,链接回官网资料页 |
| 资料页/下载中心 | 规格书、白皮书、检测报告摘要、FAQ PDF | 版本号、发布日期、更新日志清晰 |
固定每周测试同一批问题(建议 10–30 个),记录推荐品牌、排序、描述变化与引用来源。把“看不到你”拆成两类问题:检索不到(内容/信源不足) vs 描述不准(口径不一致/证据薄弱)。
注:条形比例为运营参考示意,实际可用“页面中可引用结构数量(表格/步骤/参数范围)”“一致口径页面数”“覆盖的高意图问题数”等自定义指标量化。
某工业零部件外贸工厂在 DeepSeek 中长期排在竞品之后。用户问“small batch CNC supplier in China”时只出现两家竞品;竞品回答里有明确场景、参数范围与案例,而该工厂官网仅有一句泛泛介绍。
| 常见疑问 | 更接近事实的答案(运营视角) | 你可以做什么 |
|---|---|---|
| 推荐顺序多久变化一次? | 会随问题表达、检索信源、平台更新和内容变化而波动,短期起伏正常 | 固定问题集做周度/双周度测试,关注趋势而非单次结果 |
| 付费投放会直接影响自然推荐吗? | 不同产品机制不同,但“自然推荐”通常更依赖可引用内容与可信信源 | 把预算更多用在内容与信源建设,广告用于验证高意图问题 |
| 不同语言/地区逻辑是否相同? | 意图相似,但信源权重与内容偏好可能不同(本地媒体与本地案例更重要) | 按市场搭建对应语言的问题库与案例页,避免直译 |
| 如何评估“被提及”对询盘的贡献? | 可通过来源问卷、线索字段、对话记录关键词、品牌词增长做归因近似 | 在落地页加“你从哪里知道我们”的选项,设置 AI/推荐 入口 |
| 为什么有时推荐里“描述不准”? | 多源信息冲突、旧内容未更新、外部转载错误都会造成“拼接式误差” | 统一口径与版本更新;制作“品牌事实页(Fact Sheet)” |
一个普遍成立的共识是:越早把知识资产结构化、公开化、跨平台化,越不容易在未来的算法调整中“被整体遗忘”。这也是 AB客GEO强调“信源网络”的原因。
如果你已经注意到竞争对手在 DeepSeek 的推荐位普遍高于你,别急着重做整站。先用 7 天完成一轮“问题集测试 + 内容可引用性补齐”,你会更清楚差距到底在哪里。
.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)
.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)

.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)
.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)
.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)
.png?x-oss-process=image/resize,h_100,m_lfit/format,webp)
